2025年9月15日,复旦大学陈树渠比较政治发展研究中心举办的年度主题演讲第15期(总第384期)在文科楼615会议室成功举行。谢菲尔德大学信息、新闻与传播学院迈克·瑟沃尔(Mike Thelwall)教授受邀以“Deepseek与ChatGPT能否评估学术研究质量?”为主题发表学术演讲。讲座由复旦大学国际关系与公共事务学院唐莉教授主持,俄亥俄州立大学公共事务教授卡罗琳·瓦格纳(Caroline Wagner)、复旦大学社会科学高等研究院青年研究员王宇、复旦大学全球公共政策研究院副教授柳美君担任与谈人,吸引了华东师范大学、上海财经大学等校内外众多师生积极参与。
学术研究的质量评估长期以来一直是学术界的核心挑战。无论是期刊论文出版、职称申请或晋升,还是科研机构绩效评估,传统方法多依赖专家评审或引用数量,常常耗费大量人力和财力。针对这一现状,瑟沃尔教授探讨了大语言模型(Large Language Model, LLM)在学术质量评估中的应用潜力,并试图回答两个关键问题:其一,LLM是否具备一定程度评估学术研究质量的能力?其二,引用数量、专家评审和LLM等不同类型的证据分别能为学术评估提供何种支持?

一、LLM在评估学术研究质量中的作用
瑟沃尔教授采用英国2021年“卓越研究框架”(Research Excellence Framework, REF)的评估标准作为大语言模型(LLM)的输入,来模拟专家对科研成果的评审过程。REF 2021由34个学科单元的1120位资深专家参与,从原创性、重要性和严谨性三个维度,对157所英国高等教育机构的185,594项科研成果(主要为期刊论文)进行了四分制评估(世界领先、国际优秀、国际认可、国内认可)。
瑟沃尔教授展示了ChatGPT对一篇关于跨国跨学科学术合作模式论文的评估结果,显示其评分与专家判断总体一致。进一步使用ChatGPT 4o对大量论文进行模拟评估,并以专家评分作为基准的结果显示:其一,ChatGPT 4o生成的研究质量评分与专家评估之间的正相关性高于传统引用数量指标。其二,在除临床医学外,ChatGPT 4o在各学科的相关性普遍优于引用量指标。其三,无论输入完整全文,或是仅提供标题与摘要,LLM给出的评估结果类似。其四,其他LLM(如Deepseek、Gemini)的评分也与专家判断呈正相关,且模型规模与表现呈正比,参数过小的模型(如10亿参数)可靠性不足。
针对推理型大语言模型(Reasoning LLMs),瑟沃尔教授指出其在评估学术文章时会尝试明确考虑更广泛的上下文。例如,DeepSeek R1 8b能具体分析研究方法对现有技术的延续性,从而对原创性做出细化判断;而ChatGPT 4o则倾向于提供概括性评价,侧重逻辑性、方法稳健性和结果完整性,较少深入分析方法创新性。
同时,瑟沃尔教授也警示了LLM在学术评估中的风险。他指出,LLM可能无法区分真实研究与虚构或讽刺内容,从而产生不合理评价。例如,对于荒诞的研究标题《松鼠外科医生产生更多引用影响吗?》,多个LLM仍按照科学研究标准认真评估并给出不错的评分;但当被直接询问“松鼠能写论文吗”时,LLM能正确否定,凸显其常识推理与逻辑匹配的局限性。
总体而言,尽管LLM可能出现明显错误,但是从统计角度来看,其评分可靠性优于随机判断。在评审意见分歧或缺乏足够专业知识和时间评估期刊文章时,LLM可提供辅助参考。然而,正式同行评审仍然必不可少,否则会被视为草率或不严谨。
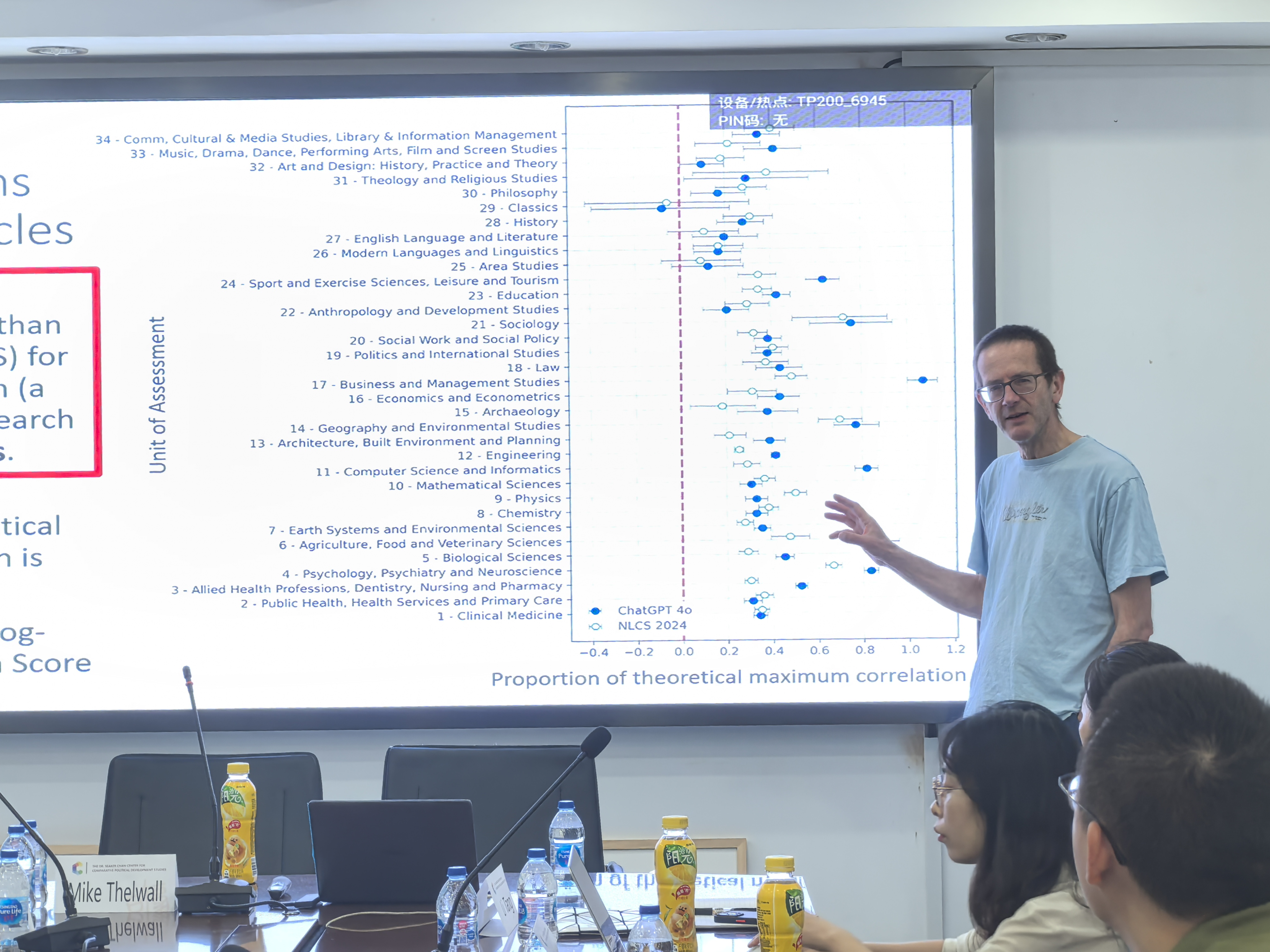
二、比较不同的评估学术方法:专家评审vs.引用数量vs. ChatGPT
学术论文的质量评估通常涵盖原创性、严谨性与影响力三个核心维度,其中影响力可进一步区分为科学影响力与社会影响力。引用量主要反映科学影响力,仅能体现研究质量的部分面向,而同行评审在此方面通常更具全面性和准确性。
围绕引用数量与研究质量的重要性,学界存在较大争议。按照默顿的科学社会学观点,未被引用的研究成果价值存疑。因此,高被引通常是研究实用性的体现,低被引研究则易被忽视。然而,瑟沃尔教授提出不同见解:多数引用的实际价值有限,引用数量并不能直接衡量研究影响力。科研的最终目标在于服务社会,而非仅仅为学术界提供参考;引用更多体现的是对后续研究的支撑功能(例如综述类文章易获高被引)。科研出版的部分目的在于认证、奖励或巩固研究者,因此,即使某些研究未产生直接实用价值,但是对其产出的认可仍在研究者层面产生核心系统性益处。
对于LLM的评估,其支持者认为模型不存在人类的偏见。但瑟沃尔教授指出,LLM并非真正“评估”研究,只是基于语言模式进行推测,可靠性有限。然而,由于专家也会出现分歧和错误,且不一定精通所评估的领域,因此LLM虽然不是理论上近乎完美的评估者,但是在某些场景下可能比传统同行评审更为高效、经济。
LLM在评估学术研究质量的方面已与传统的引用指标不相上下,甚至在多个学科领域表现更佳。LLM的突出优势在于其不仅能够衡量科研的学术影响,还可覆盖更广泛的贡献维度,而且能够即时应用于最新研究成果,并可根据不同的研究质量标准进行灵活定制。然而,LLM的局限性也不可忽视,例如非科研应用可能面临版权限制、可能产生系统性偏差,数据获取和使用的便捷性尚不及引用指标。
然而,LLM在科研评价中的应用仍需在以下方面审慎考虑:若评估结果直接影响学术职业生涯,其使用是否符合伦理与法律规范?LLM评估究竟会激励高质量研究,还是会导致学者撰写“机器友好型”摘要或添加机器可读指令?将LLM的评估结果与专家审稿和引用数据结合,是否能提供新的、有益的视角?在中国,使用LLM进行评估是否涉及已发表研究的版权问题?

最后,唐莉老师感谢了迈克·瑟沃尔教授的精彩分享。瓦格纳教授、王宇青年研究员、刘美君副教授分别对瑟沃尔教授的分享进行富有洞见的点评。随后,迈克·瑟沃尔教授同与会的老师和同学进一步对相关问题进行了深入的交流与探讨,本次讲座圆满结束。


